


-
The photorealistic integration of virtual content into real-world scenes has long been recognised as a central challenge for immersive display technologies, including virtual reality (VR), augmented reality (AR), and mixed reality (MR)1–3. The theoretical core of these systems is the plenoptic function, which provides a comprehensive description of the spatial and angular distributions of light rays4. Faithful reproduction of a dynamic light field requires a rigorous solution to the rendering equation, which accounts for the intricate coupling between incident illumination, scene geometry, and material reflectance5,6. This interplay ultimately determines photometric consistency, that is, whether virtual objects appear visually anchored within a scene or as perceptually detached overlays7.
However, the capture and reproduction of high-fidelity light fields under dynamic conditions present a formidable inverse problem. Conventional approaches typically rely on hardware-intensive acquisition setups such as light stages or dense multi-view camera arrays to adequately sample environmental illumination8,9. However, in many immersive scenarios, available observations are constrained to a sparse viewpoint, often corresponding to a single perspective from a wearable headset. Neural radiance fields (NeRFs), while effective for view synthesis10, often exhibit baked-in illumination, where lighting is entangled with scene geometry and appearance11–13. This entanglement makes it difficult to adapt rendered content to changing real-world lighting, resulting in visual inconsistencies whenever the observer or illumination conditions change. These constraints reveal a fundamental mismatch between the assumptions of many illumination-dependent rendering strategies and the sensing realities of mixed-reality systems.
Although many existing approaches continue to rely on access to complete illumination information, such as panoramic environmental maps or densely sampled views, these assumptions rarely hold true in practical mixed-reality settings. The recent work of Hong et al. provides a significant contribution by shifting the focus from exhaustive illumination acquisition to a perceptually sufficient framework for estimating and editing illumination from a single observation14–18. Recognising that exact recovery of global illumination from a single view is an ill-posed problem, the authors demonstrated that the essential elements of illumination can be inferred from minimal visual input. As illustrated in Fig. 1, this method bypasses the intractable task of full-environment recovery by utilising minimal visual input to drive a generative process that updates the neural light fields in a controllable and photometrically consistent manner. The conceptual workflow introduced by Hong et al. demonstrated a paradigm shift from physical reconstruction to generative synthesis. Based on a single sparse observation, the system inferred compact and explicit illumination cues (intensity, direction, and semantic descriptors). These cues act as physical priors to guide a generative network that dynamically reconstructs and updates the neural light field, ensuring that the virtual content exhibits shading and shadows that are photometrically consistent with the evolving real-world environment.
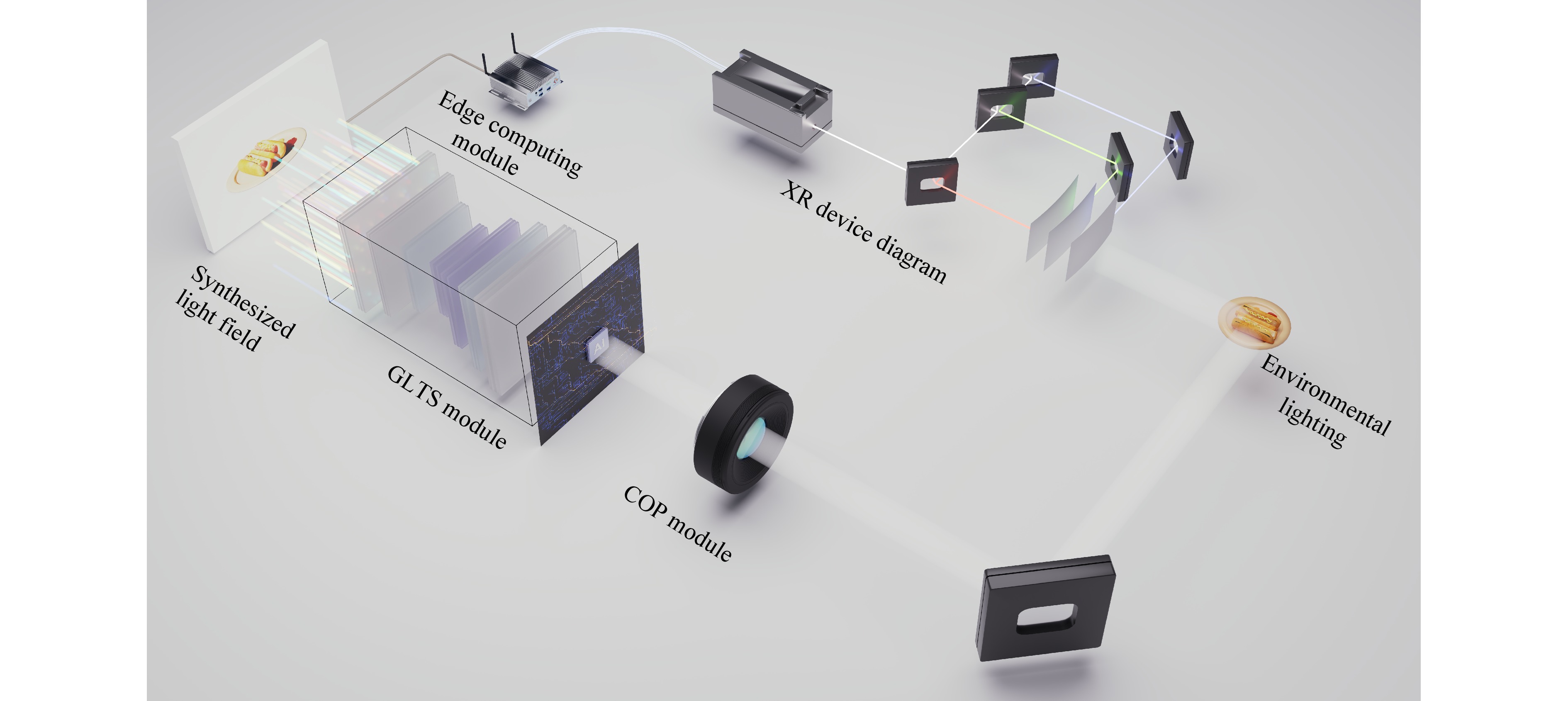
Fig. 1 Neural illumination editing pipeline for adaptive light field display.
The methodological novelty of the system lies in its ability to bridge the gap between explicit optical physics and generative semantic control. Rather than considering illumination estimation as a numerical end, the authors employed a computational optical perception (COP) module to translate sparse signals into structured parametric representations, effectively using semantic descriptors, such as text-based prompts, to constrain the solution space for light field editing. By injecting these priors into a generative synthesis engine, the framework ensures that the updated scene appearance, including complex shadows and view-dependent highlights, responds coherently to illumination variations while preserving strict geometric consistency across views19. This represents a significant departure from purely image-based style transfer, which offers a physically grounded approach to neural relighting.
The significance of these results extends beyond improvements in visual quality. This study addresses a fundamental practical constraint in mixed-reality systems by demonstrating that high-fidelity, photometrically consistent light-field editing can be achieved with an extremely sparse observation budget. This establishes a scalable pathway for adaptive light-field rendering without relying on specialised capture hardware or dense sensing. This capability is particularly relevant for real-world immersive displays, where both sensing and computation are inherently limited.
More broadly, this study is conducted at a time of growing demand for lightweight and energy-efficient computational imaging solutions. As immersive display hardware continues to evolve towards compact, glasses-free 3D platforms20,21, the demand for algorithms that maximise the perceptual impact per compute unit has become increasingly critical. The hybrid paradigm demonstrated herein, which integrates physical illumination priors with the inference capacity of generative models, is likely to inspire a new wave of research in responsive digital light fields. This approach holds particular promise for applications ranging from automotive heads-up displays to mobile AR, where maintaining visual coherence with the physical world is essential for both user immersion and comfort.
Single observation for light-field editing
- Light: Advanced Manufacturing , Article number: 57 (2026)
- Received: 19 March 2026
- Revised: 03 April 2026
- Accepted: 07 April 2026 Published online: 09 June 2026
doi: https://doi.org/10.37188/lam.2026.057
Abstract: Inferring explicit illumination cues from a single sparse observation fundamentally decouples scene representation from its captured environment. By shifting illumination from a static, baked-in attribute to a parametrically editable representation, the framework establishes a novel paradigm for scalable, photometrically consistent immersive displays under dynamic real-world conditions.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article′s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article′s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.

 DownLoad:
DownLoad: