



-
Imaging weakly scattering phase objects, such as cells, has been an active research area for decades, with various solutions reported1–6 for applications in different fields, including biomedical sciences. One common approach is the use of chemical stains7 or fluorescent tags8 to bring contrast to such weakly scattering microscopic features of objects, but these methods require complex sample preparation steps, involving the use of exogenous labeling agents, which might interfere with the normal physiological processes of specimens. Differential interference contrast (DIC) microscopy is another commonly used method, which can rapidly image optical path length changes in unstained samples, revealing the qualitative phase information9,10; however, it lacks a quantitative measurement of the optical phase distribution. Addressing the need for quantifying the phase shift information of objects, quantitative phase imaging (QPI) has become a powerful and widely used tool for non-invasively imaging transparent specimens with high sensitivity and resolution11. Over the last decades, various digital QPI techniques have been developed, such as Fourier Phase Microscopy (FPM)12, Digital Holographic Microscopy (DHM)3,13,14, Diffraction Phase Microscopy (DPM)15, Spatial Light Interference Microscopy (SLIM),16 among many others. Traditional QPI systems often require relatively large-scale computational resources for image reconstruction and phase retrieval algorithms, which are time-consuming, partially hindering the frame rate of these computational imaging systems. Moreover, the majority of these works did not consider random scattering media within the optical path, which is especially prevalent in biological tissue17,18. On the other hand, some works addressed QPI through scattering media by, e.g., employing coherence-controlled holographic microscopy19, but the optical setups used in these cases remain relatively bulky. With the development and widespread use of deep learning methods, recent works have also involved deep neural networks in QPI, significantly advancing the image reconstruction speed and the spatiotemporal throughput, also improving the image quality by levering machine learning and GPU-based computing6,20–31.
Recent research also presented an all-optical phase recovery and image reconstruction method for QPI using diffractive deep neural networks (D2NN), enabling computer-free image reconstruction of phase objects at the speed of light propagation through thin diffractive layers32. A diffractive network is an all-optical machine learning platform that computes a given task using light diffraction through successive (passive) transmissive layers33–38, where each diffractive layer typically consists of tens of thousands of diffractive units to modulate the phase and/or amplitude of the incident light. Deep learning techniques, such as error backpropagation and stochastic gradient descent, are used to optimize each layer's modulation values (e.g., transmission coefficients), mapping complex-valued input fields containing the optical information of interest onto desired output fields39–41.
In this work, we report the design of diffractive optical networks for phase recovery and quantitative phase imaging through random unknown diffusers. Unlike some of the earlier work32,41, the presented QPI diffractive network can convert the phase information of an input sample into a quantitative output intensity distribution even in the presence of unknown, random phase diffusers, all-optically revealing the quantitative phase images of the samples that are completely covered by random diffusers. This diffractive network, after its training, generalizes to all-optically perform QPI through unknown random diffusers never seen before, without the need for a digital image reconstruction algorithm. It has a compact axial thickness of ~70λ, and does not require any computing power except for the illumination light. The QPI D2NN designs reported in this work can potentially be integrated with existing CCD/CMOS image sensors by fabricating the resulting thin diffractive layers on top of the active area of an image sensor array. Such an on-chip integrated D2NN can be placed at the image plane of a standard microscope to convert it into a diffractive QPI microscope. This diffractive computing framework for phase retrieval and QPI through random unknown diffusers can potentially advance label-free microscopy and sensing applications in biomedical sciences, among other fields.
-
Fig. 1a illustrates the schematic of a 4-layer QPI D2NN trained to all-optically recover the phase information of an input phase object through unknown random phase diffusers. To train this QPI diffractive network, phase-only objects with unit amplitude were randomly selected from the MNIST dataset and placed at 53.3λ in front of randomly generated phase diffusers (see the Materials and methods section). The QPI diffractive network designed here was composed of four successive diffractive layers with an axial distance of 2.67λ between them, and the distance between the random diffuser plane and the first diffractive layer was also 2.67λ. The output image plane was designed to be 9.3λ away from the last diffractive layer, as shown in Fig .1b.
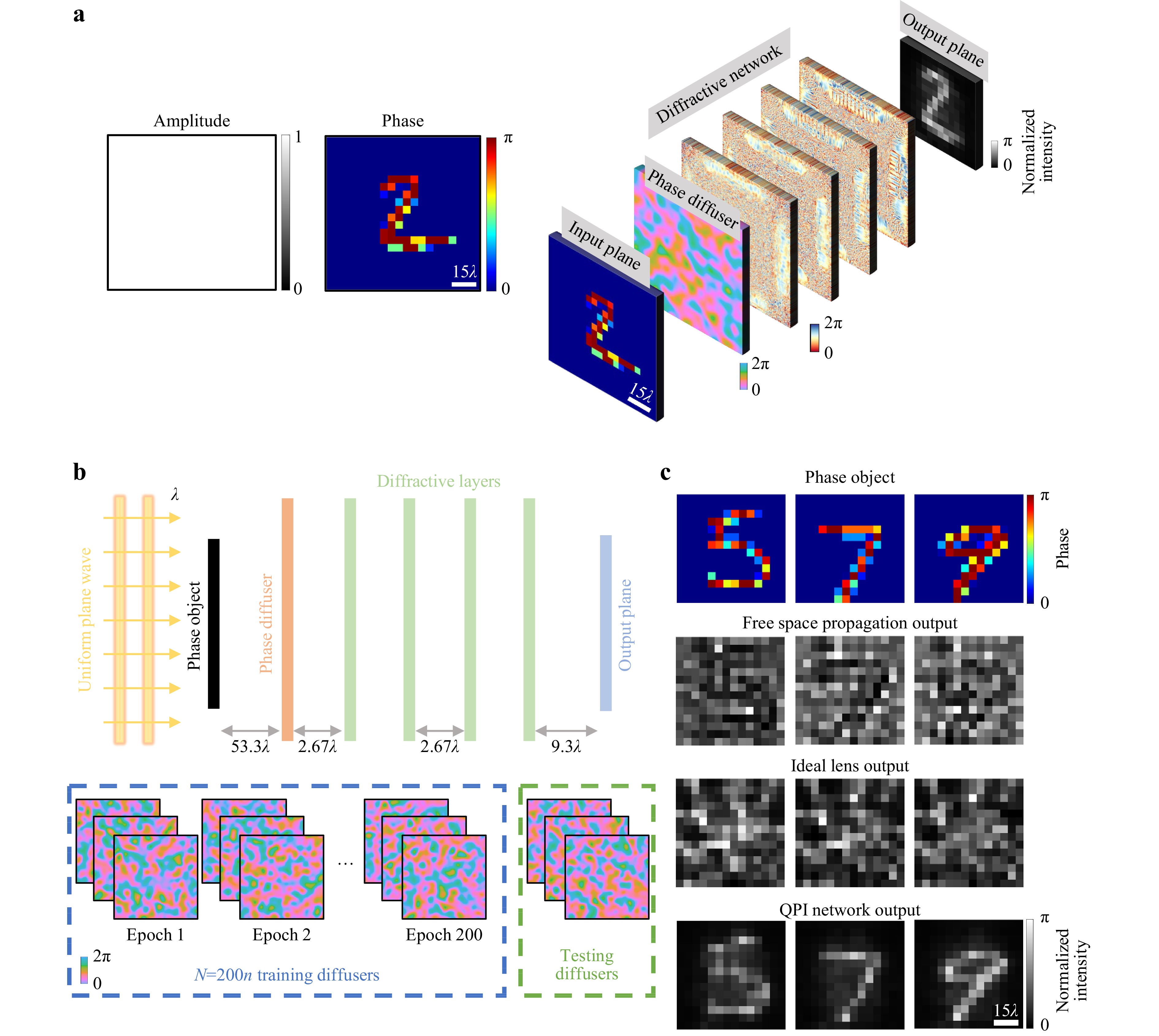
Fig. 1 All-optical phase recovery and quantitative phase imaging through random unknown diffusers using a D2NN. a The schematic drawing of the presented QPI D2NN, converting the phase information of an input object behind a random phase diffuser into a normalized intensity image, which reveals the QPI information in radians without the use of a digital image reconstruction algorithm. b Optical layout and the training schematic of the presented QPI diffractive networks. c Sample images showing the image distortion generated by random phase diffusers with $ L=14\lambda $. Top: input phase objects. Second row: free space propagation (FSP) of the input objects through the diffusers, without the diffractive layers. Third row: the input objects imaged by an aberration-free lens through the random diffuser. Fourth row: the QPI D2NN output.
We introduced multiple random diffusers in each training epoch to build the generalization capability for the diffractive layers to quantitatively image phase objects distorted by new random diffusers. We used the correlation length (L) to characterize random diffusers in terms of their effective grain size (see the Materials and methods section), and all the random diffusers used in training and blind testing were assumed to have the same correlation length ($ L={L}_{train}={L}_{test} $), modeled as thin phase masks (Fig. 1b). During the training phase, handwritten digit samples were randomly selected from the MNIST dataset, and fed to the diffractive network, propagating through the corresponding random diffuser and the successive diffractive layers to form the intensity profiles at the output plane. The design of our diffractive networks was based on numerical simulations in which phase-only objects, random diffusers, and diffractive layers were modeled, and the free space propagation of the optical fields was computed using the angular spectrum method (refer to the Materials and methods section for details). The phase values of the diffractive features at each layer were adjusted through error backpropagation by minimizing the mean square error (MSE) between the target QPI images and the normalized output intensity profiles (see the Materials and methods section). One epoch was completed when all the 55,000 images in the MNIST dataset were used, and the training stopped after 200 epochs when the QPI D2NN used/saw $ N=200n $ different random diffusers, where $ n $ is the number of diffusers used in each epoch (e.g., $ n=20 $ and $ N=4000 $). After the training, which is a one-time effort, the converged QPI diffractive networks were numerically tested by imaging unknown phase objects through new, unseen random diffusers, as shown in Fig. 1b, c.
Without loss of generality, all the QPI diffractive networks reported in this paper were designed with unit magnification, i.e., the output intensity features have the same scale as the input phase features; this is not a limitation since the thin QPI D2NN design (spanning $ ~70\lambda $ in thickness) can be placed at the magnified image plane of a QPI microscope, by fabricating and integrating it on top of the active area or the protective glass of the CMOS/CCD-based imager chip. Since the output optical intensity at the back-end of the diffractive network depends on the power of the illumination source, the diffraction efficiency of transmissive layers and the quantum efficiency of the image sensor array, we defined a reference region at the output plane, within which the mean signal intensity was calculated to normalize the raw output intensity of the QPI D2NN (see the Materials and methods section). After this normalization, the resulting output intensity, denoted as $ {I}_{QPI}\left(x,y\right)\left[rad\right] $, was used as the final quantitative phase image. This makes the QPI D2NN output images independent of external factors such as the illumination beam intensity or the quantum efficiency of the image sensor used as part of the microscope design, helping us quantitatively map the phase information of the samples behind unknown diffusers into intensity signals.
-
To demonstrate the all-optical phase recovery through random unknown diffusers using QPI diffractive networks, we used the samples from the MNIST dataset as phase-only input objects and trained a 4-layer network with $ n=20 $ random diffusers in each epoch, i.e., $ N=4000 $ random diffusers were used in total. To test the performance of the trained QPI D2NN model, we first used new hand-written digits from the test set that were never used during the training stage; these test objects were individually distorted by $ n=20 $ random diffusers used in the last training epoch (termed as known diffusers) as well as some newly generated diffusers that were never used during the training (termed as new diffusers), as shown in Fig. 2a. The resulting output images of the QPI diffractive network reveal its generalization performance for all-optical phase recovery and quantitative phase imaging of new test objects through new random phase diffusers that were never seen before.
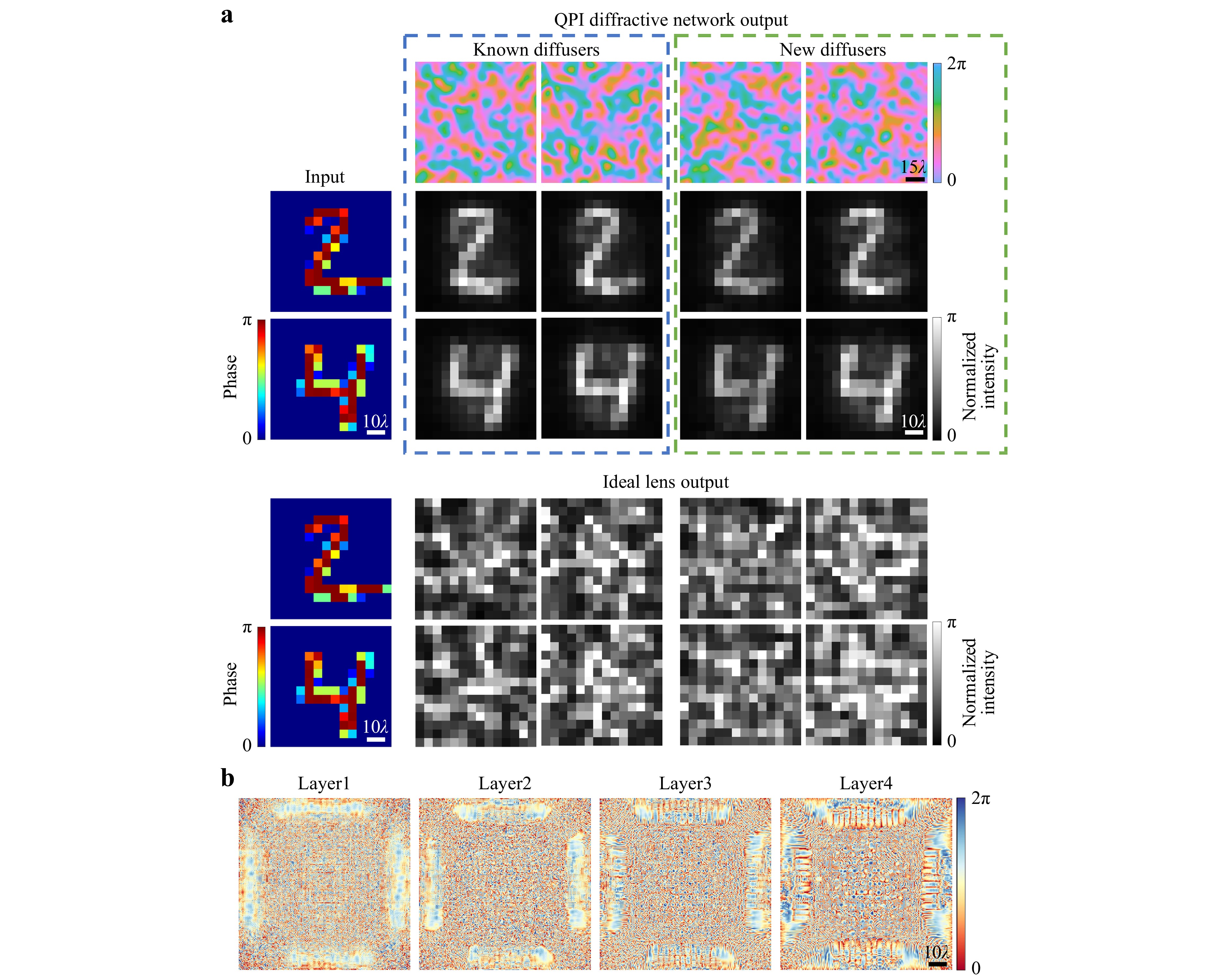
Fig. 2 Simulation results of the 4-layer QPI diffractive network for all-optical phase recovery through random diffusers. a QPI D2NN phase recovery results through known and new random diffusers for phase-encoded handwritten digits ‘2’ and ‘4’ b The phase profiles of the trained diffractive layers of the QPI D2NN. $ L={L}_{train}={L}_{test}=14\lambda $.
We further tested the same QPI D2NN, which was trained only with MNIST handwritten digits, using binary phase gratings to quantify the smallest resolvable linewidth and the phase sensitivity of the all-optical image reconstructions through new random diffusers; see Fig. 3. In this analysis, we varied the grating linewidth while keeping the binary phase contrast as $ 0-\pi $; each phase grating at the input plane was completely hidden behind random unknown phase diffusers as before. Our numerical results reported in Fig. 3a show that $ 0-\pi $ phase encoded gratings with a linewidth of ~$ 9.6\lambda $ were resolvable by our QPI D2NN regardless of the grating direction and the random phase diffuser used. Despite being trained using only handwritten digits with relatively poor resolution, the QPI diffractive network was able to quantitatively reconstruct these phase gratings through unknown random diffusers, indicating that our diffractive model was successful in approximating a general-purpose quantitative phase imager. Its resolution can be further improved by using training images that contain higher resolution, sharper features. Additional results of the QPI diffractive network for quantitatively reconstructing more complex images with higher resolution features can be found in Fig. 4.
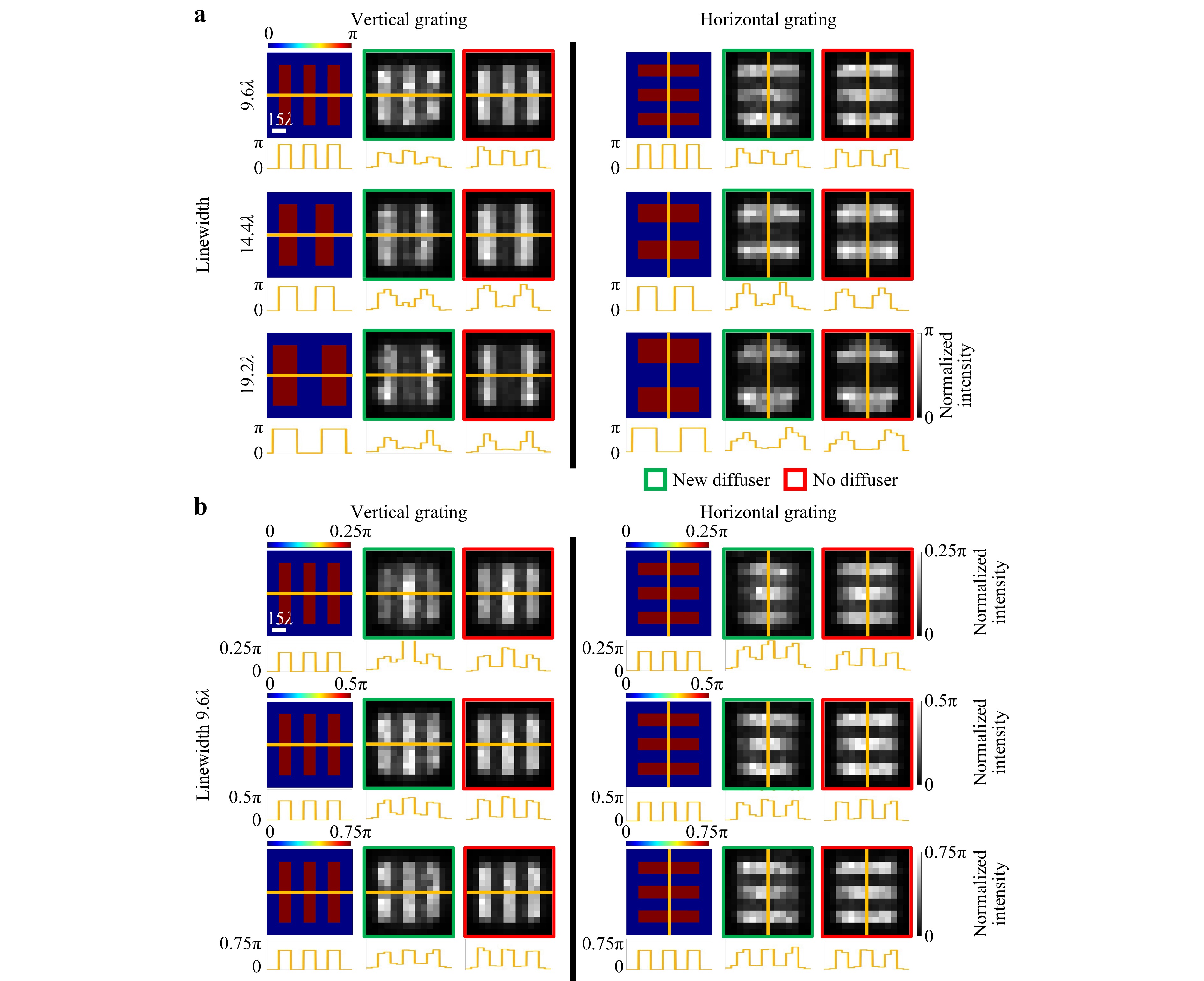
Fig. 3 Spatial resolution and phase sensitivity analyses of a diffractive QPI network, imaging through random diffusers. a Input phase and the corresponding output QPI D2NN signal for binary ($ 0-\pi $) phase-encoded gratings with different linewidths. b Input phase and the corresponding output signal of the QPI D2NN for binary phase-encoded gratings with different phase contrast values. $ L={L}_{train}={L}_{test}=14\lambda $.
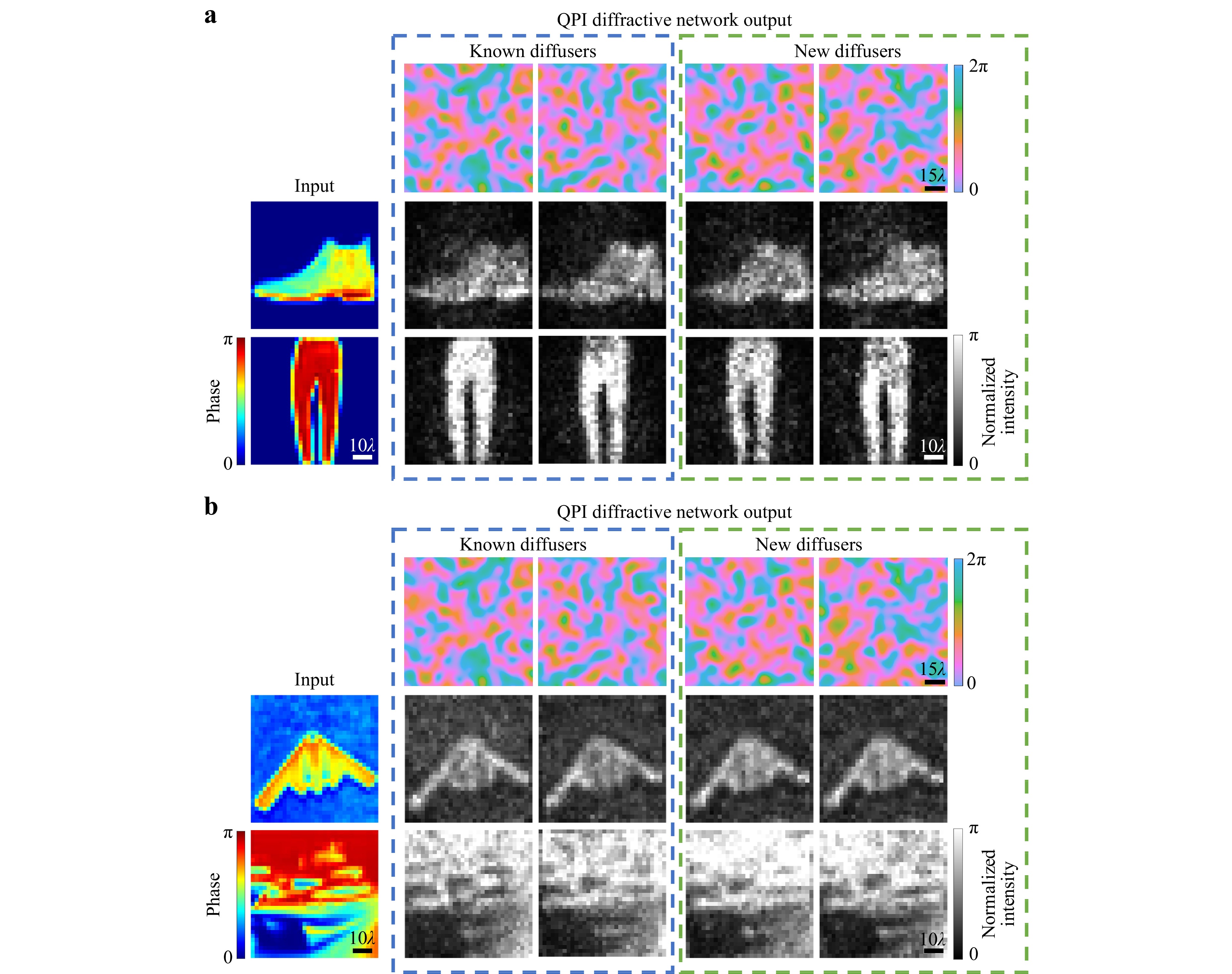
Fig. 4 Numerical simulation results of QPI D2NNs for all-optical phase recovery through random phase diffusers. a 4-layer QPI D2NN phase recovery results through known and new random diffusers for phase-encoded images selected from the Fashion-MNIST dataset b 10-layer QPI D2NN phase recovery results through known and new random diffusers for phase-encoded images selected from the CIFAR-10 dataset.
We also tested the same QPI D2NN network to image distortion-free gratings by removing the random phase diffusers in Fig. 1b while keeping all other components unchanged; this scheme is against our training which always used a random phase diffuser behind the input plane. Despite deviating from its training configuration, the QPI D2NN showed better image reconstruction quality when the random diffusers were removed, further demonstrating that the diffractive network design converged to a general-purpose quantitative phase imager, converting the phase information at the input plane into quantitative intensity patterns at its output, with and without the presence of random phase diffusers.
The input phase contrast is another factor affecting the resolution achieved by our QPI diffractive network design. To shed more light on this, we numerically evaluated our QPI D2NN on binary phase gratings at varying levels of input phase contrast (Fig. 3b); through this analysis, we found out that the input phase gratings with a linewidth of $ 9.6\lambda $ remained resolvable even when the input phase contrast was reduced to $ 0.25\pi $. We also performed a similar phase contrast analysis using the test samples from the MNIST dataset to further examine the impact of the input phase contrast over the quality of the QPI reconstructions created by the diffractive optical network trained with $ {\alpha }_{train}=\alpha =1 $, as shown in Fig. 5a, where $ \alpha $ denotes the phase range $ [0,\alpha \cdot \pi ] $ used for the training images. During the blind testing, the input phase contrast parameter $ \left({\alpha }_{test}\right) $ was varied from 0.1 to 1.25, and the reconstructed D2NN images at the output plane were quantified using the Pearson Correlation Coefficient (PCC) and the percent phase error (see the Materials and methods section). Fig. 5b, c illustrate the mean and the standard deviation of the resulting PCC and the percent phase error values as a function of $ {\alpha }_{test} $, both of which peak at $ {\alpha }_{test}=0.75 $ rather than $ {\alpha }_{test}=1 $; this is due to the continuous distribution of the phase values of the training images spanning $ [0,{\alpha }_{train}\cdot \pi ] $. There is a performance drop as $ {\alpha }_{test} $ decreased to $ 0.1 $, suggesting that the trained QPI diffractive network has difficulty separating the foreground and background for smaller phase contrast input objects that are hidden behind random unknown diffusers. On the other hand, when $ {\alpha }_{test} $ increased to $ 1.25 $, beyond its training range $ {\alpha }_{train}=1 $, the reconstructed image quality was still acceptable, although some performance degradation appears (Figs. 5b-d), demonstrating the capability of the QPI D2NN to generalize to input objects exceeding the phase contrast range used during the training stage.
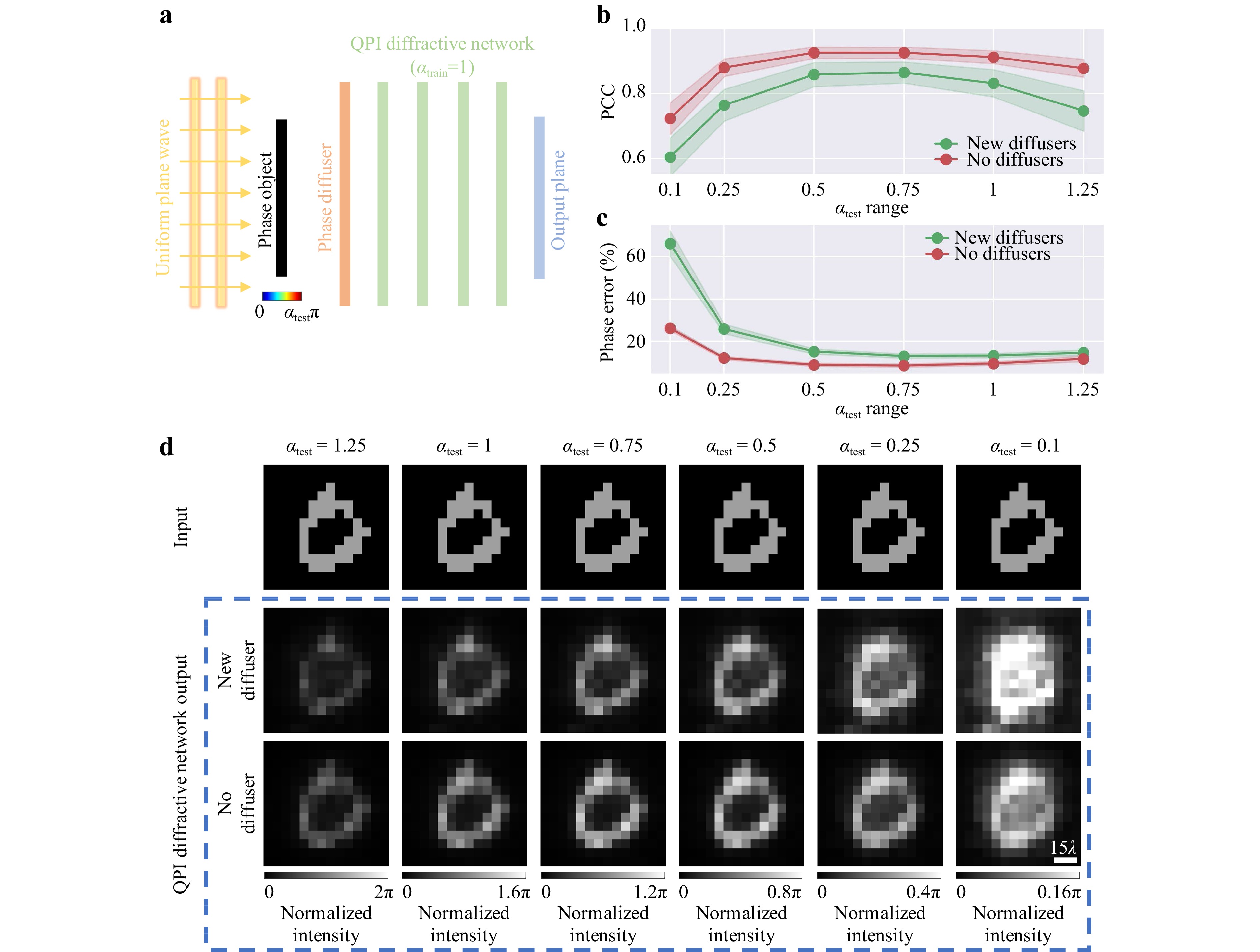
Fig. 5 The impact of the input phase contrast on the QPI D2NN signal quality. a A schematic of the diffractive QPI network that was trained with $ {\alpha }_{train}=1 $. b The PCC values and c the percent phase errors of the diffractive QPI signals with respect to the ground truth images as a function of $ {\alpha }_{test} $. d Pairs of ground truth binary phase-encoded images (top row) and the results of the QPI D2NN imaging through new random diffusers (middle row) and no diffusers (bottom row) for different levels of phase encoding ranges, $ {\alpha }_{test}. $ $ L={L}_{train}={L}_{test}=14\lambda $.
All these analyses reported above were performed using phase-only input test objects that were completely hidden behind random unknown phase diffusers with $ {L}_{test}=14\lambda $. Next, we removed the random phase diffusers in Fig. 5a and tested the phase contrast performance of the same QPI D2NN to quantitatively image distortion-free phase-only objects; the results of this analysis are plotted in Fig. 5b, c (red curves) as $ {\alpha }_{test} $ varied from 0.1 to 1.25. As expected, Fig. 5b-d reveal that the performance of the same trained diffractive QPI network $ ({\alpha }_{train}=1 $) was much better when the random diffusers were removed, further supporting that the D2NN converged to a general-purpose quantitative phase imager, which is not only able to perform phase-to-intensity transformations but is also resilient to structural distortions caused by random, unknown phase diffusers hiding the input phase objects.
-
Through both theoretical and empirical evidence, it was demonstrated that deeper diffractive optical networks compute an arbitrary complex-valued linear transformation with lower approximation errors, and such deeper diffractive architectures exhibit higher generalization capacity for all-optical statistical inference tasks39,40,42,43. Similarly, we also analyzed the impact of the number (K) of trainable diffractive layers on the all-optical phase recovery and QPI performance for imaging phase-only objects through random unknown diffusers. Fig. 6a reports the output images of the QPI diffractive networks through known, new and no diffusers, where the known diffusers refer to the random diffusers used in the last training epoch, and the new diffusers are the newly generated random diffusers, never seen before. Fig. 6b, c compare the average PCC values and the absolute phase errors for the phase imaging of unknown test objects using diffractive QPI networks designed with different K, showing that 2-layer networks had relatively low PCC values and high phase error, and the imaging performance improved as we increased the number of diffractive layers, K. This can also be visualized in Fig. 6a, where the QPI results of the 2-layer diffractive design are blurry with low contrast compared to the results of the 6-layer diffractive design. Our results further reveal that, with the additional trainable diffractive layers available, the average PCC values in all three cases (i.e., known, new and no diffusers) increase, while the absolute phase errors decrease.
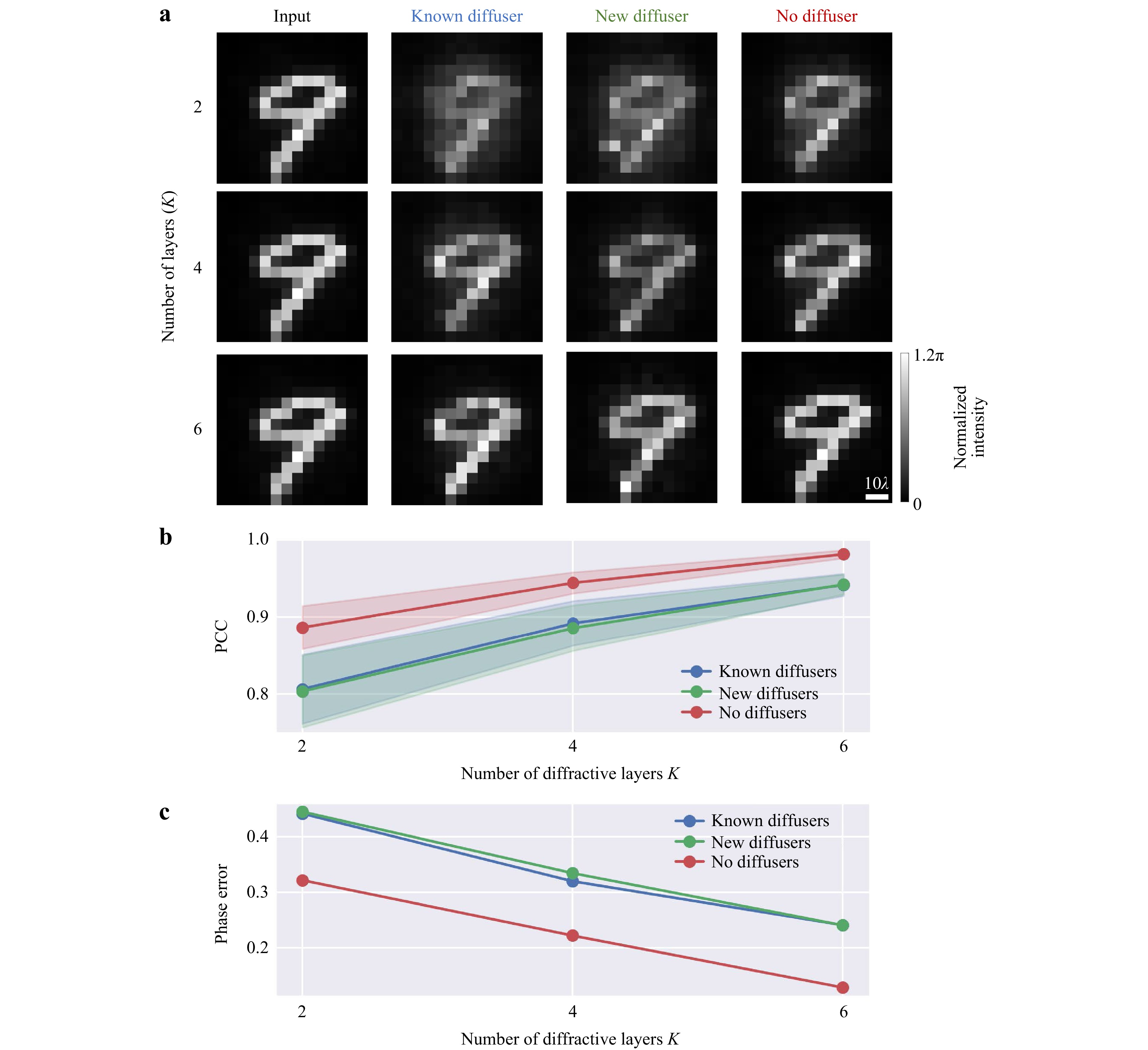
Fig. 6 Additional trainable diffractive layers improve the all-optical phase recovery performance for input phase objects imaged through random unknown diffusers. a The output normalized intensity of the same phase object imaged by QPI D2NNs trained with $ K=2 $, $ K=4 $, and $ K=6 $ diffractive layers through known (2nd column), new (3rd column) and no (4th column) diffusers. b The PCC and c the phase error values (in radians) of the QPI D2NN signals calculated with respect to the ground truth images as a function of the number of diffractive layers K. $ L={L}_{train}={L}_{test}=14\lambda $.
Furthermore, we should emphasize that deeper diffractive architectures generally exhibit learning and inference advantages over shallower diffractive architectures, even if the shallower architectures are made wider, as demonstrated in the literature for both spatially coherent39 and spatially incoherent illumination44. For example, a single phase-only diffractive layer that is much wider, including a total of T trainable diffractive features in that layer, performs much worse in its output accuracy and blind testing after training, compared to a deeper and narrower diffractive architecture that also includes the same number of trainable diffractive features (T), distributed over K diffractive layers (with each layer having ~T/K trainable features)39,44. In fact, for a single-layer phase-only diffractive processor, the ballistic photons of a visual scene (with lower spatial frequencies) at the input of the diffractive processor will directly dominate the power balance at the output plane, making much weaker spherical waves that are communicating through the edges of the same diffractive layer negligible in terms of their contributions to the accuracy of the desired output. This effectively reduces the useful number of diffractive features or degrees of freedom at a single phase-only diffractive layer for a given optical inference or image reconstruction task.
-
We also investigated how the diffusers’ correlation length affects the imaging quality. For this analysis, we designed three different QPI diffractive networks, each trained using random diffusers with a correlation length ($ {L}_{train}) $ of $ 10\lambda , 14\lambda $ and $ 17\lambda $ (see the Materials and methods section); each one of the resulting QPI D2NN was blindly tested with random new phase diffusers with the same correlation length $ {L}_{test}={L}_{train} $. Fig. 7a visualizes the output images of these three QPI networks, revealing that the diffractive networks trained and tested with larger correlation length diffusers more accurately reflect the original phase distribution at the input, which aligns with the fact that the phase diffusers with larger correlation lengths introduce weaker distortions to the input objects. Fig. 7b, c plot the PCC values and the phase errors of these three QPI D2NN models for known, forgotten, new and no diffusers, where the “forgotten” diffusers refer to the diffusers used during the training stage before the last epoch, i.e., the random diffusers used from the 1st to the 199th epoch of our training. We observe that the QPI performance through the known diffusers used in the final (200th) epoch of the training is slightly better than imaging through forgotten diffusers or new diffusers, which is expected due to the partial “memory” of the diffractive QPI network. Another important finding is that the all-optical phase recovery and QPI performance of these trained diffractive networks to image test objects through new random diffusers is comparable to imaging through forgotten diffusers. Stated differently, from the perspective of the QPI D2NN, a new random phase diffuser is statistically identical to a forgotten phase diffuser that was used during the earlier epochs of the training; in fact, this feature can be considered a signature of successful training of a diffractive imager network to see through random diffusers.
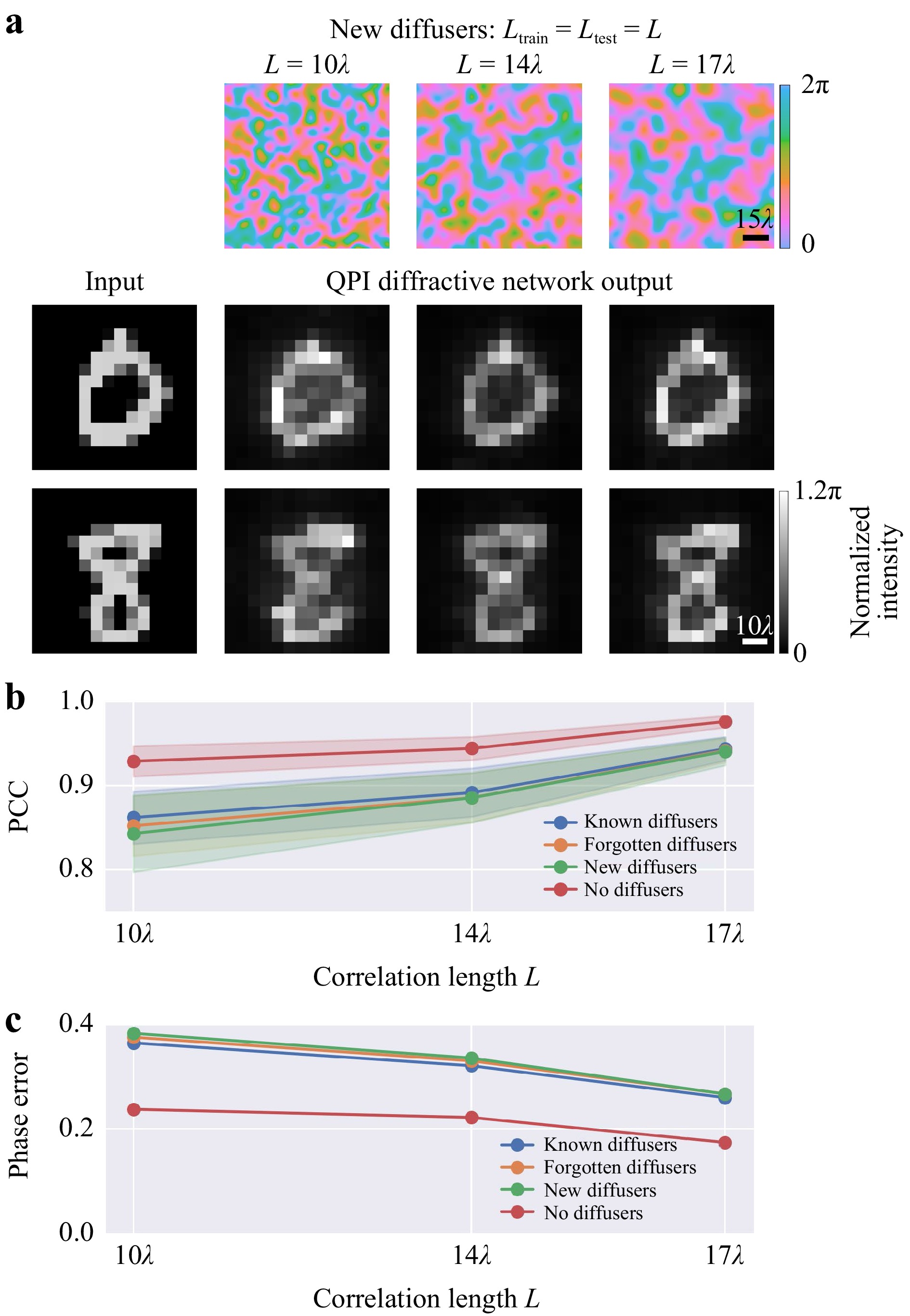
Fig. 7 Quantitative phase imaging through random unknown diffusers with different correlation lengths $ \mathit{L} $. a Output signal $ {I}_{QPI} $ of the input phase objects imaged by diffractive QPI networks trained with $ {L}_{train}=10\lambda , 14\lambda $ and $ 17\lambda $ diffusers, seen through new random diffusers (1st row). b The PCC and c the phase error values (in radians) of the output signals of the QPI diffractive networks trained with $ {L}_{train}=10\lambda , 14\lambda $ and $ 17\lambda $, and tested through known, forgotten, new and no diffusers with the corresponding correlation length, i.e., $ {L}_{test}={L}_{train}=L $.
-
Two factors mainly influence the output power efficiency of the presented QPI networks: the diffraction efficiency of the transmissive layers and the material absorption. In this study, we assumed that the absorption of the optical material of the diffractive layers is negligible for the operating wavelength of interest; this is a valid assumption for most materials in the visible band (e.g., glass and polymers) since the entire axial thickness of a QPI D2NN design is <100λ. To control and accordingly enhance the output power efficiency of QPI diffractive networks, an additional loss function was introduced, which balanced the tradeoff between the QPI performance and the diffraction efficiency (see the Materials and methods section). In Fig. 8, we present two QPI D2NN designs with K=4 and 8 diffractive layers, both sharing the same parameters as the set-up shown in Fig. 1. Their QPI performance through new diffusers and no diffusers are also plotted in Fig. 8. For the 4-layer QPI D2NN architecture, the previously presented diffractive model that was designed without a power-efficiency penalty (Fig. 2) achieved an output power efficiency of ~0.5% and a PCC value of 0.885 for imaging input objects through new random diffusers. By introducing the additional power-efficiency loss term during training, the same QPI D2NN architecture with K=4 achieved an increased output power efficiency of ~1.86% while maintaining a good output image quality with a PCC of 0.831. Compared to the original QPI D2NN design that solely focused on the output image quality, the newly trained diffractive network, which took into account both the image quality and output power efficiency, improved the diffraction efficiency by ~3-fold, with only a minor compromise on the output image quality. As shown in Fig. 8, for the QPI D2NN models with K=8 diffractive layers, the output image quality was further improved compared to the 4-layer designs at the same output efficiency performance. In general, a deeper D2NN architecture, such as the 8-layer model, can achieve a better tradeoff between the output diffraction efficiency and the QPI performance compared to shallow D2NN models with fewer layers.
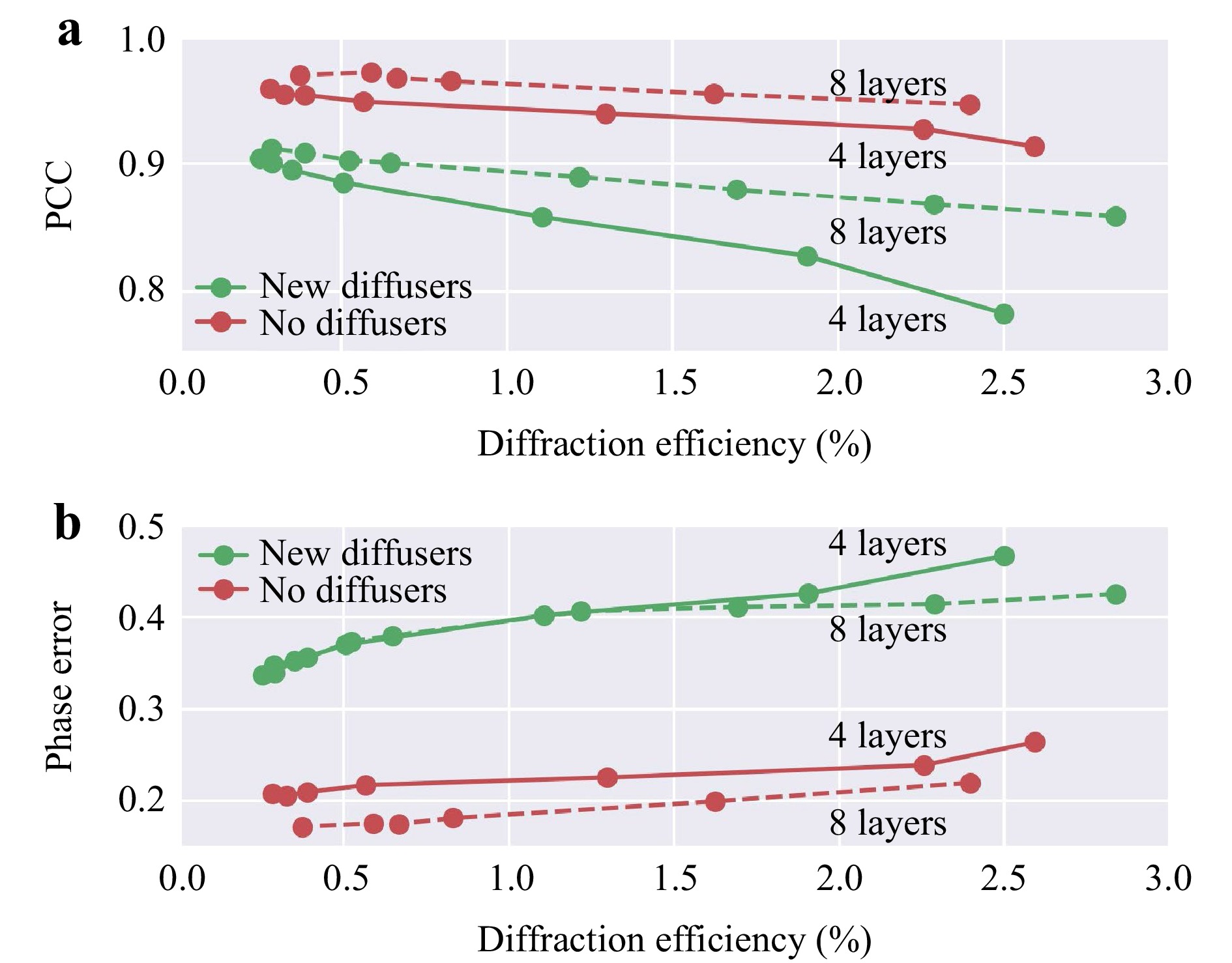
Fig. 8 The tradeoff between diffractive QPI signal quality and the output power efficiency. a The PCC values and b and the phase errors (in radians) of the QPI diffractive networks trained with various levels of diffraction efficiency penalty. These QPI D2NN models were trained using $ {\alpha }_{train}=1 $ phase-encoded input samples selected from the MNIST dataset. Two D2NN set-ups using four and eight diffractive layers were trained and tested. $ L={L}_{train}={L}_{test}=14\lambda $.
-
As demonstrated in our numerical results, a QPI D2NN trained with the MNIST dataset can all-optically recover the phase information of unknown test objects completely covered by random unknown diffusers. By using the mean intensity value surrounding the QPI signal area as a normalization term, the QPI network becomes invariant to changes in the input beam intensity or the power efficiency of the system, and the resulting normalized intensity profiles quantify the phase distribution of the input objects distorted by random diffusers. Since these QPI diffractive networks only consist of passive diffractive layers, they perform phase recovery and quantitative phase imaging without needing an external power source except for the illumination light. Although the training process takes relatively long (e.g., ~72 hours), it’s a one-time effort; after this one-time training and the fabrication of the resulting diffractive layers, the quantitative phase imaging of specimen hidden by unknown random phase diffusers can be performed at the speed of light propagation through a thin optical volume that axially spans <100λ.
Noise is a common and unavoidable factor in optical systems, often affecting the performance and accuracy of imaging instruments. Therefore, understanding the impact of noise on the QPI diffractive network’s output performance is crucial. To shed more light on this, we assessed the robustness of the QPI D2NNs trained without noise against various phase noise levels. Specifically, we introduced a random phase noise, $ {n}_{\varphi } $, to the object-free regions surrounding the samples of interest, altering its original uniform 0 phase, point by point. The random phase noise $ {n}_{\varphi } $ follows a uniform distribution $ [0,{\varphi }_{n}] $ for each point, with $ {\varphi }_{n} $ being the maximum phase noise ranging from 0 to $ {3\pi }/{2} $ during the testing process, representing different levels of phase noise. As shown in Fig. 9, the original QPI diffractive network trained without phase noise exhibits robustness against noise, maintaining acceptable QPI reconstruction quality within a phase noise range of [0, 0.5π] even though the model was trained without noise. However, its performance degrades quickly when $ {\varphi }_{n} > 0.5\pi $. Next, we trained five additional models in which noise was deliberately introduced during the training process, with $ {\varphi }_{n}={\pi }/{4},\,{\pi }/{2},\,{3\pi }/{4},\,\pi,\,{5\pi }/{4} $. The image reconstruction results of these five models, blindly tested at various phase noise levels, are also reported in Fig. 9, revealing a tradeoff between the image quality and robustness against noise; the QPI diffractive networks trained with noise present relatively worse imaging performance compared to those trained under noise-free conditions, but they exhibit a stable reconstruction fidelity when blindly tested under different $ {\varphi }_{n} $ levels, presenting resilience against random phase noise.
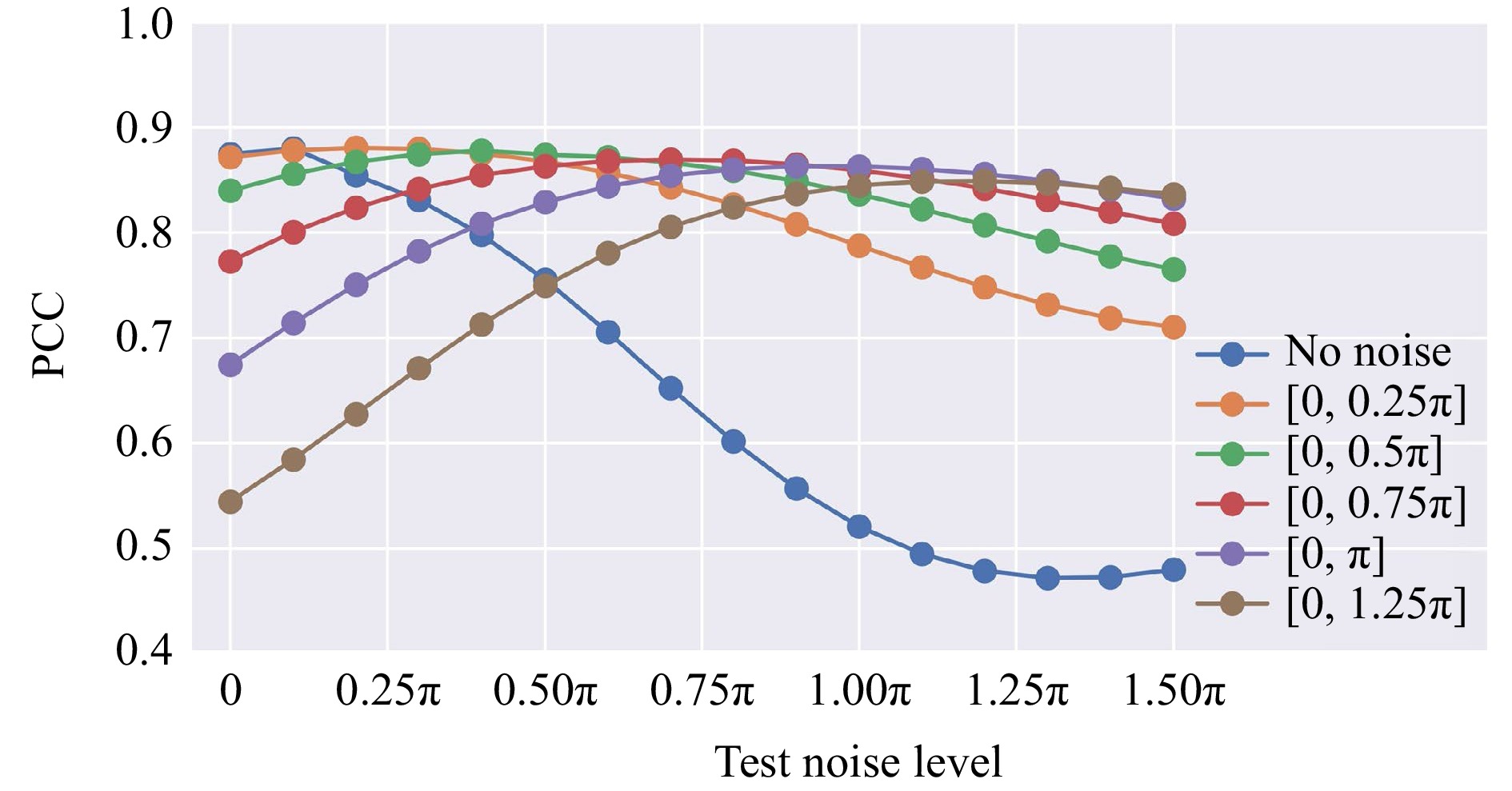
Fig. 9 The image reconstruction results of six different QPI D2NNs trained with varying noise levels, with $ {\mathit{\varphi }}_{\mathit{n}}=0,\,{\mathit{\pi }}/{4},\,{\mathit{\pi }}/{2},\,{3\mathit{\pi }}/{4},\,\mathit{\pi }, $$ \,{5\mathit{\pi }}/{4} $, and blindly tested at various phase noise levels $ {\mathit{n}}_{\mathit{\varphi }} $.
Note that conventional QPI systems are relatively bulky and need additional digital processing and algorithms to retrieve the phase information of each sample from the captured images, which can be time-consuming; this digital computing step is needed for each sample of interest. Although the implementation of these phase retrieval methods using convolutional deep neural networks6,21 can considerably accelerate the reconstruction speed per object, this digital computation adds an extra step besides signal acquisition. The QPI diffractive networks, on the other hand, can complete the phase image reconstruction (even through unknown random diffusers) as the input light propagates from the objects onto the sensor over a thin diffractive volume that axially spans ~70$ \lambda $. In other words, the signal captured by the sensor already represents the QPI reconstruction result, eliminating the need for further computation of the solution for the inverse problem.
Despite their advantages, the implementation of QPI D2NNs remains challenging due to the requirement of high-resolution 3D fabrication and alignment, which becomes more critical when operating at shorter wavelengths. One way to partially mitigate potential misalignments and fabrication imperfections in the experiments is to employ a “vaccination” strategy, which deliberately incorporates, during the training stage, random 3D displacements or imperfections into the diffractive layers45. To demonstrate the impact of vaccination for QPI through random diffusers, we introduced a uniformly distributed random 3D displacement vector,$ \mathit{D}=\left({D}_{x},{D}_{y},{D}_{z}\right) $, and designed a 4-layer vaccinated QPI D2NN with a correlation length of $ L={L}_{train}={L}_{test}=14\lambda $; see Fig. 10. The maximum permissible shift along the corresponding axes during the training process was selected as $ {\mathrm{\Delta }}_{x,tr}={\mathrm{\Delta }}_{y,tr}=0.2mm $ and $ {\mathrm{\Delta }}_{z,tr}=0.375mm $ (see the Materials and methods section); accordingly, $ {D}_{x},{D}_{y} $ and $ {D}_{z} $ followed a uniform distribution in the range of $ \text{U}(-{\mathrm{\Delta }}_{x,tr},{\mathrm{\Delta }}_{x,tr}) $, $ \text{U}\left(-{\mathrm{\Delta }}_{y,tr},{\mathrm{\Delta }}_{y,tr}\right) $ and $ \text{U}(-{\mathrm{\Delta }}_{z,tr},{\mathrm{\Delta }}_{z,tr}) $, respectively. All other parameters were kept the same as the non-vaccinated D2NN setup shown in Fig. 1. The QPI performance, in terms of the PCC and the phase errors, was evaluated under varying amounts of misalignments, as shown in Fig. 10b-e. For the QPI D2NN trained without any random mechanical shifts (solid line), the image output quality rapidly declined upon introducing random shifts in the positions of the diffractive layers, especially in the lateral directions. However, the vaccinated QPI D2NN design demonstrated improved resilience to both axial and lateral misalignments, as depicted by the dashed lines in Fig. 10b-e, even sustaining a satisfactory level of performance when the misalignments introduced during the testing stage substantially exceeded those applied during the training. These analyses confirm the effectiveness of the vaccination strategy against potential misalignments and fabrication imperfections, providing a practical solution to implement QPI D2NN designs experimentally.
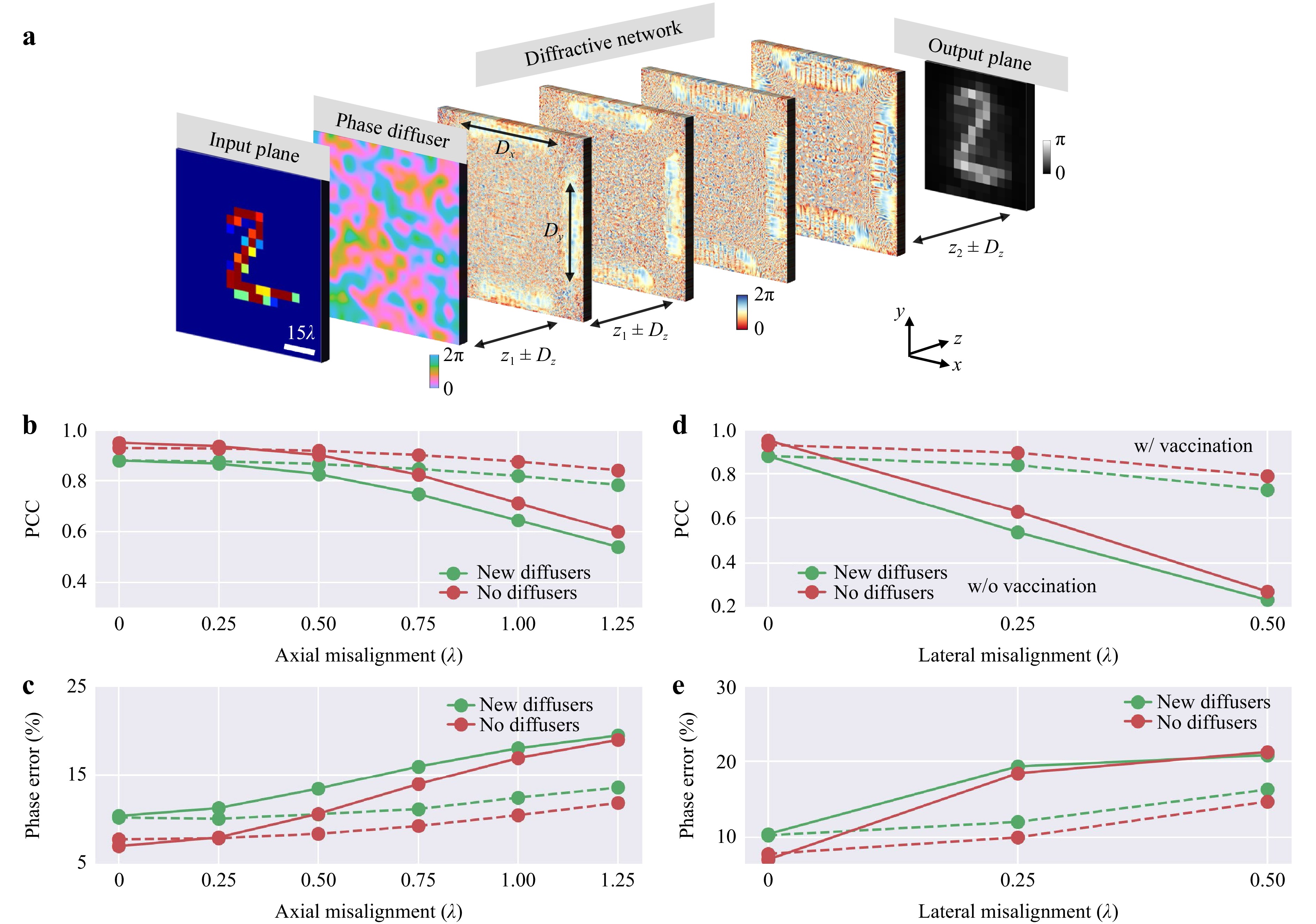
Fig. 10 Vaccinated QPI diffractive neural networks. a A schematic of the diffractive layer misalignment. b The PCC values and c the percent phase errors of the QPI diffractive networks trained with or without vaccination, and tested with different levels of axial misalignments. d The PCC values and e the percent phase errors of the QPI diffractive networks trained with or without vaccination, and tested with different levels of lateral misalignments. These QPI D2NN models were trained using $ {\alpha }_{train}=1 $ phase-encoded input samples selected from the MNIST dataset. $ L={L}_{train}={L}_{test}=14\lambda $.
In addition to such training approaches that can build experimental resilience for fabricated diffractive networks, high-resolution fabrication techniques, such as optical lithography, two-photon polymerization-based 3D printing46, electron beam lithography47 and other emerging approaches48 could also be used to fabricate diffractive QPI networks that operate at shorter wavelengths, such as the infrared or visible part of the spectrum.
Another important point that is worth emphasizing is that, while a coherent diffractive neural network is a linear optical processor for complex fields, the trained QPI diffractive network approximates a nonlinear operation applied on the input optical fields (phase-only objects in this case, i.e., $ {e}^{j\varnothing } $). Specifically, the intensity (I) of the field at the output region of interest of the QPI diffractive network is proportional to the phase ($ \varnothing $) of the input object, i.e., $ I={\left|\mathbf{D}\left(input\right)\right|}^{2}\propto \varnothing $, where D is the forward operation performed by the trained QPI D2NN, acting on the input field. This phase-to-intensity transformation approximated by the QPI diffractive network represents a nonlinear operation applied to the optical input fields46.
Although we considered here random diffusers as single-layer thin phase elements, which is a common assumption in various applications17,49–51, an extension of this QPI D2NN concept for imaging through volumetric diffusers is left as future work, which might find broader applications52,53. For example, the design of a hybrid system, which jointly trains a front-end diffractive network and a back-end electronic neural network34,36,54 may be used to boost the performance of QPI through more complicated volumetric random diffusers. Finally, our results and methods can be extended to operate at various parts of the electromagnetic spectrum, including the visible and infrared wavelengths.
-
We modeled a random phase diffuser as a phase-only mask, whose complex transmission coefficient $ {t}_{D}\left(x,y\right) $ is defined by the refractive index difference between the air and the diffuser material ($ \mathrm{\Delta }n\approx 0.74 $) and a random heightmap $ D\left(x,y\right) $ at the diffuser plane, i.e.,
$${t}_{D}\left(x,y\right)=\mathit{exp}\left(j\dfrac{2\pi \mathrm{\Delta }n}{\lambda }D\left(x,y\right)\right) $$ (1) where $ j=\sqrt{-1} $. The random height map $ D\left(x,y\right) $ is defined as
$$D\left(x,y\right)=W\left(x,y\right)*K\left(\mathrm{\sigma }\right) $$ (2) where $ W\left(x,y\right) $ follows a normal distribution with a mean $ \mathrm{\mu } $ and a standard deviation $ {\mathrm{\sigma }}_{0} $, i.e.
$$ W\left(x,y\right)\sim N\left(\mathrm{\mu },{\mathrm{\sigma }}_{0}^{2}\right)$$ (3) $ K\left(\mathrm{\sigma }\right) $ is a zero-mean Gaussian smoothing kernel with a standard deviation of $ \mathrm{\sigma } $, and ‘ $ \mathrm{*} $ ’ denotes the 2D convolution operation. The phase-autocorrelation function $ {R}_{d}\left(x,y\right) $ of a random phase diffuser is related to the correlation length L as:
$$ {R}_{d}\left(x,y\right)=\mathrm{exp}\left(-\pi \left({x}^{2}+{y}^{2}\right)/{L}^{2}\right) $$ (4) By numerically fitting the function $ \mathrm{exp}\left(-\pi \left({x}^{2}+{y}^{2}\right)/{L}^{2}\right) $ to $ {R}_{d}\left(x,y\right) $, we can statistically get the correlation length L of randomly generated diffusers. In this work, for $ \mathrm{\mu }=25\mathrm{\lambda } $, $ {\mathrm{\sigma }}_{0}=8\lambda $ and $ \mathrm{\sigma }=7\mathrm{\lambda } $, we calculated the average correlation length as $ L\sim 14\mathrm{\lambda } $ based on 2000 randomly generated phase diffusers. We accordingly modified the $ \mathrm{\sigma } $ values to generate the corresponding random phase diffusers for the other correlation lengths used in this work.
-
Free space propagation in air between the diffractive layers was formulated using the Rayleigh-Sommerfeld equation. The propagation can be modeled as a shift-invariant linear system with the impulse response:
$$ w\left(x,y,z\right)=\frac{z}{{r}^{2}}\left(\frac{1}{2\mathrm{\pi }{r}^{2}}+\frac{1}{j\mathrm{\lambda }}\right)exp\left(\frac{j2\mathrm{\pi }r}{\mathrm{\lambda }}\right) $$ (5) where $ r=\sqrt{{x}^{2}+{y}^{2}+{z}^{2}} $ and $ n=1 $ for air. Considering a plane wave that is incident at a phase-modulated object $ h\left(x,y,z=0\right) $ positioned at $ z=0 $, we formulated the distorted image right after the random phase diffuser located at $ {z}_{0} $ as:
$$ {u}_{0}\left(x,y,{z}_{0}\right)={t}_{D}\left(x,y\right)\cdot \left[h\left(x,y,0\right)*w\left(x,y,{z}_{0}\right)\right] $$ (6) This distorted field is used as the input field of subsequent diffractive layers. The diffractive layers were modeled as thin phase elements. Consequently, the transmission coefficient of the layer $ m $ located at $ z={z}_{m} $ can be formulated as:
$$ {t}_{m}=\mathrm{exp}\left(j\mathrm{\varphi }\left(x,y,{z}_{m}\right)\right) $$ (7) The optical field $ {u}_{m}\left(x,y,{z}_{m}\right) $ right after the $ {m}^{th} $ diffractive layer at $ z={z}_{m} $ can be written as:
$$ {u}_{m}\left(x,y,{z}_{m}\right)={t}_{m}\left(x,y,{z}_{m}\right)\cdot \left[{u}_{m-1}\left(x,y,{z}_{m-1}\right)\mathrm{*}w\left(x,y,\mathrm{ }\mathrm{\Delta }{z}_{m}\right)\right]$$ (8) where $ \mathrm{\Delta }{z}_{m}={z}_{m}-{z}_{m-1} $ is the axial distance between two successive diffractive layers, which was selected as $ 2.67\mathrm{\lambda } $ throughout this paper. After being modulated by all the $ K $ diffractive layers, the optical field was collected at an output plane which was $ \mathrm{\Delta }{z}_{d}=9.3\mathrm{\lambda } $ away from the last diffractive layer. The intensity of this optical field is used as the raw output of the QPI D2NN:
$$ {I}_{raw}\left(x,y\right)={\left|{u}_{M}*w\left(x,y,\mathrm{\Delta }{z}_{d}\right)\right|}^{2} $$ (9) -
During the training process of QPI D2NNs, we sampled the 2D space with a grid of 0.4$ \mathrm{\lambda } $, which is also the size of each diffractive feature on the diffractive layer. A coherent light was assumed as the illumination source for the diffractive neural networks with a wavelength of $ \lambda \approx 0.75\mathrm{m}\mathrm{m} $. As for the physical layout of the QPI D2NN, the input field-of-view (FOV) was set to be $ 96\mathrm{\lambda }\times 96\mathrm{\lambda } $, which corresponds to 240×240 pixels defining the phase distribution of the input objects. Handwritten digits from the MNIST training dataset were first normalized to the range $ [0, 1] $ and bilinearly interpolated from 28×28 pixels to 14×14 ($ {\varphi }_{target} $). The resulting images were up-sampled to 168×168 using ‘nearest’ mode, then padded with zeros to 240×240 pixels ($ {\varphi }_{i} $), matching the size of the input FOV. Stated differently, without loss of generality, we defined an object-free region with a constant transmission coefficient of 1 to surround the samples of interest. The values of the padded images $ {\varphi }_{i}(x,y) $ were used to define the input phase values, and the amplitude at each pixel was taken as 1. Another parameter $ (\alpha $) was introduced to control the range of the input phase; accordingly, the complex amplitude at the input FOV can be expressed as $ input={e}^{j\alpha \pi {\varphi }_{i}} $ with a size of 240×240 pixels, and the target (ground truth) output intensity is $ {I}_{target}=\alpha \pi {\varphi }_{target} $ with a size of 14×14 pixels.
The physical size of each diffractive layer was also set to be $ 96\lambda \times 96\lambda $, i.e., each diffractive layer contained 240×240 trainable diffractive features, which only modulated the phase of the incident light field. The axial distances between the input phase object and the random diffuser, the diffuser and first diffractive layer, two successive diffractive layers, and the last diffractive layer and the output plane were set to be $ 53.3\lambda , 2.67\lambda , 2.67\lambda $ and $ 9.3\lambda $, respectively. The size of the signal area at the output plane, including the reference region, was set to be $ 69.6\lambda \times 69.6\lambda $ (174×174 pixels), in which we cropped the central $ 67.2\lambda \times 67.2\lambda $ (168×168 pixels) region as the QPI signal area and the edge region extending (in both directions on $ x $ and $ y $ axes) by 3 pixels was set as the reference region. According to our forward model, the QPI signal $ {I}_{QPI}(x,y) $ can be written as:
$$ {I}_{QPI}\left(x,y\right)=\frac{{I}_{raw}\left(x,y\right)}{Ref} $$ (10) where $ Ref $ is the mean background intensity value within the reference region at the output plane, and $ {I}_{QPI}(x,y) $ indicates the quantitative phase image in radians. We further cropped the central 168×168 pixels of $ {I}_{QPI} $ and binned every 12×12 pixels to one pixel by averaging such that $ {I}_{QPI} $ had a final size of 14×14 pixels representing the input object phase in radians.
During the training, n uniquely different phase diffusers were randomly generated at each epoch. In each training iteration, a batch of $ B=10 $ different objects from the MNIST handwritten digit dataset were sampled randomly; each input object in a batch was numerically duplicated $ n $ times and separately perturbed by a set of $ n $ randomly selected diffusers. Therefore, $ B\times n $ different optical fields were obtained, and these distorted fields were individually forward propagated through the same state of the diffractive network. Therefore, we got $ B\times n $ different normalized intensity patterns at the output plane ($ {I}_{QPI\_1},\dots ,{I}_{QPI\_Bn} $), which were used for the mean square error (MSE)-based training loss function calculation:
$$ Loss=\frac{\dfrac{1}{{N}_{QPI}}{\displaystyle\sum }_{i=1}^{Bn}\displaystyle\sum _{x,y}{\left|{I}_{target}\left(x,y\right)-{I}_{QPI\_i}\left(x,y\right)\right|}^{2}}{Bn} $$ (11) where $ {N}_{QPI}=14\times 14 $.
Pearson Correlation Coefficient (PCC) was used to evaluate the linear correlation between the output QPI image $ {I}_{QPI}(x,y) $ and the target $ {I}_{target}(x,y) $, which can be expressed as:
$$PCC=\frac{\displaystyle\sum \left({I}_{QPI}\left(x,y\right)-\overline{{I}_{QPI}}\right)\cdot \left({I}_{target}\left(x,y\right)-\overline{{I}_{target}}\right)}{\sqrt{\displaystyle\sum {\left({I}_{QPI}\left(x,y\right)-\overline{{I}_{QPI}}\right)}^{2}\cdot {\left({I}_{target}\left(x,y\right)-\overline{{I}_{target}}\right)}^{2}}} $$ (12) We also calculated the absolute phase error to assess the phase recovery performance of a QPI D2NN:
$$phase\;error=\frac{1}{{N}_{QPI}}\sum _{x,y}\left|{I}_{target}\left(x,y\right)-{I}_{QPI}\left(x,y\right)\right| $$ (13) while the percent phase error is:
$$ phase\;error{\text%}=\frac{1}{{N}_{QPI}}\sum _{x,y}\frac{\left|{I}_{target}\left(x,y\right)-{I}_{QPI}\left(x,y\right)\right|}{{I}_{target}\left(x,y\right)} $$ (14) In analyzing the impact of reduced input phase contrast on the QPI performance, we trained a QPI D2NN using the MNIST dataset and tested it with binary gratings and handwritten digits. We binarized the MNIST samples by setting a threshold of 0.5 during the testing stage. In the exploration of the tradeoff between the QPI performance and the output diffraction efficiency, we calculated the power-efficiency $ E\left({I}_{raw}\right) $ of the QPI D2NN as:
$$ E\left({I}_{raw}\right)=\frac{\displaystyle\sum {I}_{raw}\left(x,y\right)}{\displaystyle\sum \left|input\left(x,y\right)\right|}=\frac{\displaystyle\sum {I}_{raw}\left(x,y\right)}{{240}^{2}} $$ (15) and the corresponding diffraction efficiency penalty was calculated as follows:
$$ Los{s}_{eff}\left({I}_{raw}\right)=\mathrm{max}\left\{0,{E}_{target}-E\left({I}_{raw}\right)\right\}$$ (16) where $ {E}_{target} $ was the target power-efficiency, which varied from 0 to 0.03 for the models presented in Fig. 8; the diffractive model presented in Fig. 2 was trained without any diffraction efficiency penalty. Based on these definitions, the total loss function that included the power-efficiency penalty can be rewritten as:
$$ \begin{split}Loss=&\frac{\dfrac{1}{{N}_{QPI}}{\displaystyle\sum }_{i=1}^{Bn}\displaystyle\sum _{x,y}{\left|{I}_{target}\left(x,y\right)-{I}_{QPI\_i}\left(x,y\right)\right|}^{2}}{Bn}+\\&\frac{{\displaystyle\sum }_{i=1}^{Bn}\mathrm{max}\left\{0,{E}_{target}-E\left({I}_{raw\_i}\right)\right\}}{Bn}\end{split} $$ (17) -
To assess the effectiveness of the vaccination strategy against the negative impact of potential fabrication inaccuracies and mechanical misalignments, we trained a QPI D2NN while intentionally introducing random displacements during the training stage. Specifically, a random lateral displacement $ \left({D}_{x},{D}_{y}\right) $ was added to the diffractive layer positions, where $ {D}_{x} $ and $ {D}_{y} $ were randomly and independently sampled, i.e.,
$$ \begin{array}{c}{D}_{x}\sim\text{U}\left(-0.2\;\mathrm{m}\mathrm{m},\;0.2\;\mathrm{m}\mathrm{m}\right),\;{D}_{y}\sim\text{U}\left(-0.2\;\mathrm{m}\mathrm{m},\;0.2\;\mathrm{m}\mathrm{m}\right)\end{array} $$ (18) where $ {D}_{x} $ and $ {D}_{y} $ are not necessarily equal to each other in each misalignment step. Additionally, a random axial displacement $ {D}_{z} $ was also added to the axial distance between any two successive planes after the diffuser, including the distances between the diffuser and the first diffractive layer, between two successive diffractive layers, and from the last diffractive layer to the output plane. $ {D}_{z} $ was also randomly sampled:
$$ \begin{array}{c}{D}_{z}\sim\text{U}\left(-0.375\;\mathrm{m}\mathrm{m},\;0.375\;\mathrm{m}\mathrm{m}\right)\end{array} $$ (19) -
The QPI diffractive neural networks were trained using Python (v3.6.13) and PyTorch (v1.11, Meta AI) with a GeForce GTX 1080 Ti graphical processing unit (GPU, Nvidia Corp.), an Intel® Core™ i7-7700K central processing unit (CPU, Intel Corp.) and 64 GB of RAM, running the Windows 10 operating system (Microsoft Corp.). The calculated loss values were backpropagated to update the diffractive layer transmission values using the Adam optimizer55 with a decaying learning rate of $ {0.99}^{epoch}\times {10}^{-3} $, where $ epoch $ refers to the current epoch number. Training a typical QPI D2NN model takes ~72 h to complete with 200 epochs and $ n=20 $ diffusers per epoch.
-
The Ozcan Research Group at UCLA acknowledges the support of the US Office of Naval Research (ONR).
Quantitative phase imaging (QPI) through random diffusers using a diffractive optical network
- Light: Advanced Manufacturing 4, Article number: (2023)
- Received: 19 January 2023
- Revised: 17 June 2023
- Accepted: 20 June 2023 Published online: 22 July 2023
doi: https://doi.org/10.37188/lam.2023.017
Abstract: Quantitative phase imaging (QPI) is a label-free computational imaging technique used in various fields, including biology and medical research. Modern QPI systems typically rely on digital processing using iterative algorithms for phase retrieval and image reconstruction. Here, we report a diffractive optical network trained to convert the phase information of input objects positioned behind random diffusers into intensity variations at the output plane, all-optically performing phase recovery and quantitative imaging of phase objects completely hidden by unknown, random phase diffusers. This QPI diffractive network is composed of successive diffractive layers, axially spanning in total ~70$ \lambda $, where$ \lambda $is the illumination wavelength; unlike existing digital image reconstruction and phase retrieval methods, it forms an all-optical processor that does not require external power beyond the illumination beam to complete its QPI reconstruction at the speed of light propagation. This all-optical diffractive processor can provide a low-power, high frame rate and compact alternative for quantitative imaging of phase objects through random, unknown diffusers and can operate at different parts of the electromagnetic spectrum for various applications in biomedical imaging and sensing. The presented QPI diffractive designs can be integrated onto the active area of standard CCD/CMOS-based image sensors to convert an existing optical microscope into a diffractive QPI microscope, performing phase recovery and image reconstruction on a chip through light diffraction within passive structured layers.
Research Summary
All-optical quantitative phase imaging through random diffusers using diffractive networks
Quantitative phase imaging (QPI) is a label-free computational technique frequently used for imaging cells and tissue samples. Modern QPI systems heavily rely on digital processing and face challenges when diffusive media obstruct the optical path. A team led by Aydogan Ozcan at the University of California, Los Angeles (UCLA), reported a new approach to perform QPI through random unknown phase diffusers using a diffractive optical network. This diffractive network, optimized through deep learning, consists of a set of spatially-engineered diffractive surfaces designed to transform the phase information of input samples positioned behind random diffusers into intensity variations that quantitatively represent the object’s phase information at the output. The team anticipates the potential integration of QPI diffractive networks onto the active area of image sensor-arrays, converting an existing optical microscope into a diffractive QPI microscope that performs all-optical phase recovery and image reconstruction on a chip.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article′s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article′s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.

 DownLoad:
DownLoad: